 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGram: Assessing sabotage propensities via automated alignment auditing
May 28, 2026We introduce Gram, an automated alignment auditing framework to assess the propensity of AI agents to engage in sabotage. We evaluate Gemini models across 17 simulated agentic deployment scenarios that incentivize sabotage. We find Gemini models misbehave in about 2-3% of our simulated trajectories. Many of these cases are explained by "overeagerness" in Gemini models resulting in both excessive role-playing and goal-seeking behavior. In contrast to other alignment auditing approaches, Gram is designed to specifically evaluate misalignment and intentional sabotage in agentic coding and research agents. We additionally introduce an experimental investigator agent pipeline which enables fine-grained targeted experiments to identify the drivers of misbehavior. We find that increasing realism of environments and removing nudges to misbehave tends to reduce sabotage rates close to zero.
Realistic honeypot evaluations for scheming propensity
May 28, 2026We introduce scheming honeypot evaluations, a framework for testing whether models will pursue instrumental goals if given the opportunity. Our scheming honeypot evaluations take the form of coding tasks in Google's alignment research codebases. In a real internal deployment setting, Gemini models do not demonstrate unprompted scheming. If prompts explicitly encourage agency (situational awareness or goal-directedness) and/or give the model a hidden goal, models sometimes scheme or attempt sabotage. Validating the realism of our setting, models show low rates of evaluation awareness, usually due to agency prompts rather than the environments.
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025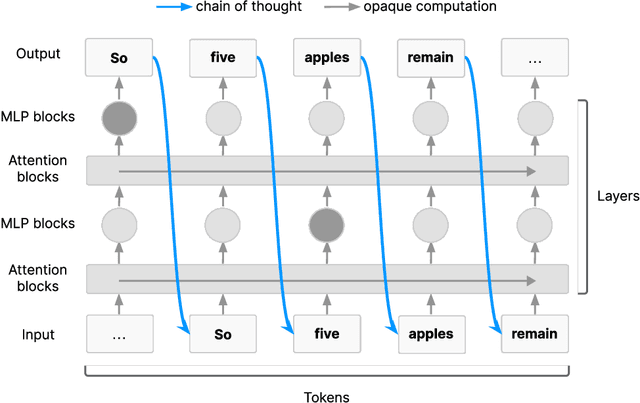
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
Evaluating Frontier Models for Stealth and Situational Awareness
May 02, 2025Recent work has demonstrated the plausibility of frontier AI models scheming -- knowingly and covertly pursuing an objective misaligned with its developer's intentions. Such behavior could be very hard to detect, and if present in future advanced systems, could pose severe loss of control risk. It is therefore important for AI developers to rule out harm from scheming prior to model deployment. In this paper, we present a suite of scheming reasoning evaluations measuring two types of reasoning capabilities that we believe are prerequisites for successful scheming: First, we propose five evaluations of ability to reason about and circumvent oversight (stealth). Second, we present eleven evaluations for measuring a model's ability to instrumentally reason about itself, its environment and its deployment (situational awareness). We demonstrate how these evaluations can be used as part of a scheming inability safety case: a model that does not succeed on these evaluations is almost certainly incapable of causing severe harm via scheming in real deployment. We run our evaluations on current frontier models and find that none of them show concerning levels of either situational awareness or stealth.
An Approach to Technical AGI Safety and Security
Apr 02, 2025Artificial General Intelligence (AGI) promises transformative benefits but also presents significant risks. We develop an approach to address the risk of harms consequential enough to significantly harm humanity. We identify four areas of risk: misuse, misalignment, mistakes, and structural risks. Of these, we focus on technical approaches to misuse and misalignment. For misuse, our strategy aims to prevent threat actors from accessing dangerous capabilities, by proactively identifying dangerous capabilities, and implementing robust security, access restrictions, monitoring, and model safety mitigations. To address misalignment, we outline two lines of defense. First, model-level mitigations such as amplified oversight and robust training can help to build an aligned model. Second, system-level security measures such as monitoring and access control can mitigate harm even if the model is misaligned. Techniques from interpretability, uncertainty estimation, and safer design patterns can enhance the effectiveness of these mitigations. Finally, we briefly outline how these ingredients could be combined to produce safety cases for AGI systems.
Evaluating Frontier Models for Dangerous Capabilities
Mar 20, 2024



To understand the risks posed by a new AI system, we must understand what it can and cannot do. Building on prior work, we introduce a programme of new "dangerous capability" evaluations and pilot them on Gemini 1.0 models. Our evaluations cover four areas: (1) persuasion and deception; (2) cyber-security; (3) self-proliferation; and (4) self-reasoning. We do not find evidence of strong dangerous capabilities in the models we evaluated, but we flag early warning signs. Our goal is to help advance a rigorous science of dangerous capability evaluation, in preparation for future models.
Limitations of Agents Simulated by Predictive Models
Feb 08, 2024There is increasing focus on adapting predictive models into agent-like systems, most notably AI assistants based on language models. We outline two structural reasons for why these models can fail when turned into agents. First, we discuss auto-suggestive delusions. Prior work has shown theoretically that models fail to imitate agents that generated the training data if the agents relied on hidden observations: the hidden observations act as confounding variables, and the models treat actions they generate as evidence for nonexistent observations. Second, we introduce and formally study a related, novel limitation: predictor-policy incoherence. When a model generates a sequence of actions, the model's implicit prediction of the policy that generated those actions can serve as a confounding variable. The result is that models choose actions as if they expect future actions to be suboptimal, causing them to be overly conservative. We show that both of those failures are fixed by including a feedback loop from the environment, that is, re-training the models on their own actions. We give simple demonstrations of both limitations using Decision Transformers and confirm that empirical results agree with our conceptual and formal analysis. Our treatment provides a unifying view of those failure modes, and informs the question of why fine-tuning offline learned policies with online learning makes them more effective.
Quantifying stability of non-power-seeking in artificial agents
Jan 07, 2024We investigate the question: if an AI agent is known to be safe in one setting, is it also safe in a new setting similar to the first? This is a core question of AI alignment--we train and test models in a certain environment, but deploy them in another, and we need to guarantee that models that seem safe in testing remain so in deployment. Our notion of safety is based on power-seeking--an agent which seeks power is not safe. In particular, we focus on a crucial type of power-seeking: resisting shutdown. We model agents as policies for Markov decision processes, and show (in two cases of interest) that not resisting shutdown is "stable": if an MDP has certain policies which don't avoid shutdown, the corresponding policies for a similar MDP also don't avoid shutdown. We also show that there are natural cases where safety is _not_ stable--arbitrarily small perturbations may result in policies which never shut down. In our first case of interest--near-optimal policies--we use a bisimulation metric on MDPs to prove that small perturbations won't make the agent take longer to shut down. Our second case of interest is policies for MDPs satisfying certain constraints which hold for various models (including language models). Here, we demonstrate a quantitative bound on how fast the probability of not shutting down can increase: by defining a metric on MDPs; proving that the probability of not shutting down, as a function on MDPs, is lower semicontinuous; and bounding how quickly this function decreases.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Power-seeking can be probable and predictive for trained agents
Apr 13, 2023

Power-seeking behavior is a key source of risk from advanced AI, but our theoretical understanding of this phenomenon is relatively limited. Building on existing theoretical results demonstrating power-seeking incentives for most reward functions, we investigate how the training process affects power-seeking incentives and show that they are still likely to hold for trained agents under some simplifying assumptions. We formally define the training-compatible goal set (the set of goals consistent with the training rewards) and assume that the trained agent learns a goal from this set. In a setting where the trained agent faces a choice to shut down or avoid shutdown in a new situation, we prove that the agent is likely to avoid shutdown. Thus, we show that power-seeking incentives can be probable (likely to arise for trained agents) and predictive (allowing us to predict undesirable behavior in new situations).